
I hate NFS
On our network we have about 100 client computers, most of which are running Fedora 11. We have two real servers running CentOS 5.4, using DRBD to keep the virtual machine data on the two real machines in sync and Red Hat’s cluster tools for starting and stopping the virtual machines.
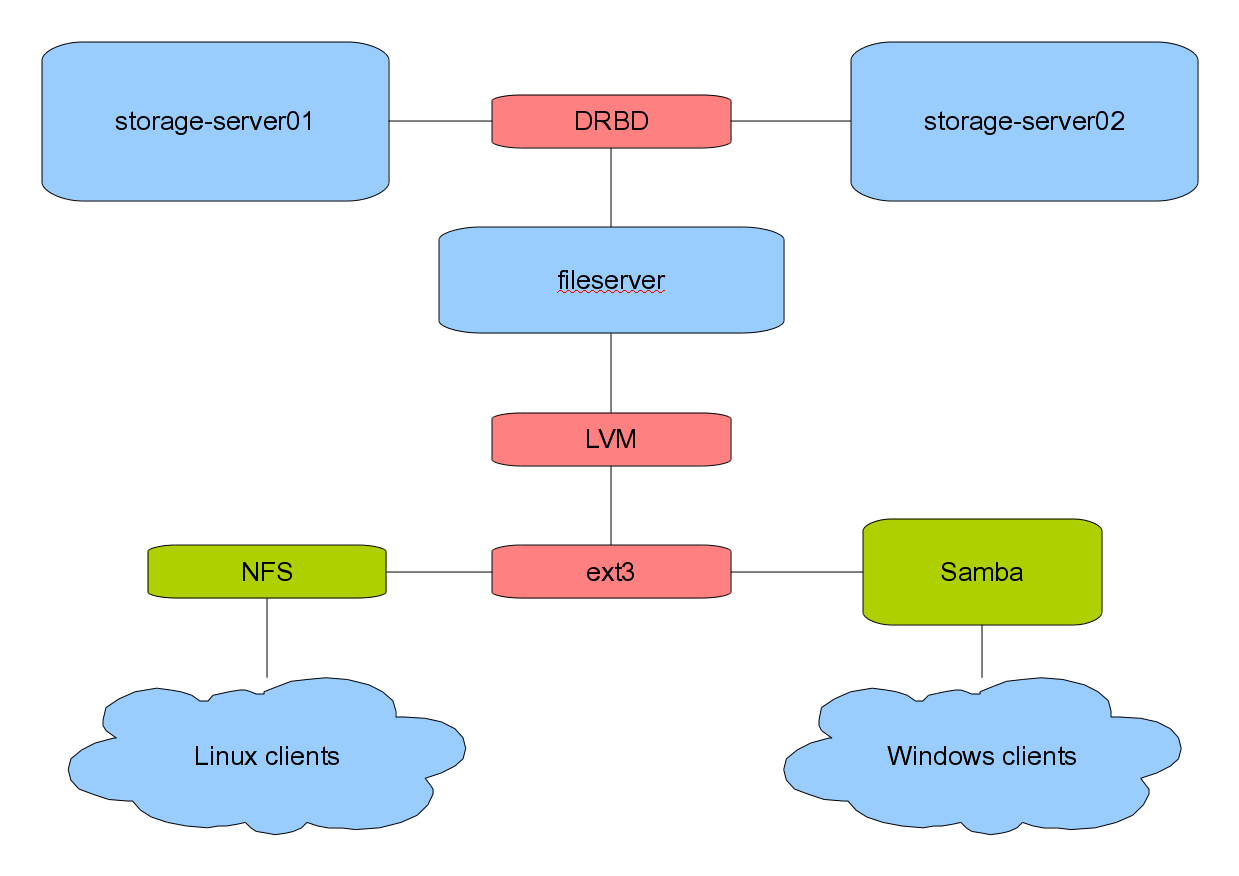
We have five virtual machines running on the two real machines, only one of which is important to this post, our fileserver.
Under our old configuration, /networld was mounted on one of the real servers, and then shared to our clients using NFS. Our virtual machine, fileserver, then mounted /networld over NFS and shared it using Samba for our few remaining Windows machines (obviously, a non-optimal solution).

There were a couple of drawbacks to this configuration:
- I had to turn on and off a number of services as the storage clustered service moved from storage-server01 to storage-server02
- Samba refused to share a nfs4-mounted
/networld, and, when mounted using nfs3, the locking daemon would crash at random intervals (I suspect a race condition as it mainly happened when storage-server0x was under high load).
My solution was to pass the DRBD disks containing /networld to fileserver, and allow fileserver to share /networld using both NFS and Samba, which seemed a far less hacky solution.
I knew there would be a slight hit in performance, though I’m using virtio to pass the hard drives to the virtual machine, so I would expect a maximum of 10-15% degradation.
Or not. I don’t have any hard numbers, but once we have a full class logging in, the system slows to a crawl. My guess would be that our Linux clients are running at 1/2 to 1/3 of the speed of our old configuration.
The load values on fileserver sit at about 1 during idle times and get pumped all the way up to 20-40 during breaks and computer lessons.
So now I’m stuck. I really don’t want to go back to the old configuration, but I can’t leave the system as slow as it is. I’ve done some NFS tuning based on miscellaneous sites found via Google, and tomorrow will be the big test, but, to be honest, I’m not real hopeful.
(To top it off, I spent three hours Friday after school tracking down this bug after updating fileserver to CentOS 5.4 from 5.3. I’m almost ready to switch fileserver over to Fedora.)
Comments
natxo asenjo
Sunday, Oct 25, 2009
Are you using kvm + qcow2 images by any chance as virtual machines? If yes, there is your problem. The only way (that I know of right now) to have a performing virtual nfs server is to use lvm volumes as partitions or to use a SAN with raw luns.
Otherwise, with an old server and fast scsi disks is NFS really fast.
Jonathan Dieter
Monday, Oct 26, 2009
Jonathan Dieter
Monday, Oct 26, 2009
It’s now second break. Current load average: 50.28, 39.85, 25.51
I hate NFS.
natxo asenjo
Monday, Oct 26, 2009
Bernie
Monday, Oct 26, 2009
Are you exporting async? Why is your load not 0 in idle times? How many spindles?
You’ve got a lot of indirections there. Are they all necessary?
I agree VMs are sub-optimal for low-latency I/O.
We have a beefy CentOS 5.3 server which can handle home directories for 200-300 concurrent mixed NFS/CIFS clients. We export sync, and use data=journal with large external journals (on a separate RAID-10 from the main RAID-60 volumes) and large commit intervals.
Jonathan Dieter
Monday, Oct 26, 2009
We are exporting async and have data=writeback on the filesystem. I’m not sure why the load is never 0, though I suspect that it’s because we have people on the network at all times (there are several people who live in or near the school, including myself).
I use DRBD because it seemed to be the easiest fast RAID-1-over-network setup I could find (I tried glusterfs and it failed miserably in speed). LVM is used to essentially RAID-0 two 1TB hard drives.
The main reason I would like to run all this in a VM is it makes maintenance at a low level far easier than on a real machine. For example, I’m already creating a new fileserver running Fedora, just to see if the newer kernel/packages will fix anything. If it doesn’t, I can just revert to the old fileserver.
Having said all that, I’m very quickly running out of ideas, and will probably revert to running NFS on the main server (or splitting fileserver into a pair of real machines that are clustered).
Stephen Smoogen
Monday, Oct 26, 2009
Jonathan Dieter
Tuesday, Oct 27, 2009
Re: Stephen Smoogen
The thing is that no other virtual machines (or the real server) have access to the /networld hard drives. However, they are SATA drives, so possibly the iocontrollers need to be dedicated as well?
darkfader
Monday, Mar 6, 2017